utf-8 - codificare de caractere
Unicode suportă aproape toate existenteseturi de caractere. Cea mai bună formă de codificare a caracterelor Unicode este codarea utf-8. Oferă compatibilitate cu ASCII, rezistență la coruperea datelor, eficiență și ușurință în prelucrare. Dar despre totul în ordine.
Forme de codificare
Calculatoarele funcționează cu numere nu doar caobiecte matematice abstracte, ci ca combinații de unități de stocare și prelucrare a informațiilor de dimensiune fixă - octeți și cuvinte pe 32 de biți. Standardul de codificare trebuie să țină cont de acest lucru atunci când se determină modul în care caracterele sunt reprezentate prin numere.
În sistemele informatice, sunt stocate numere întregicelule de memorie în mărime de 8 biți (1 octet), 16 sau 32 de biți. Fiecare formă de codare Unicode determină ce secvență de celule de memorie reprezintă un întreg corespunzător unui anumit caracter. Standardul oferă trei forme diferite de codificare a caracterelor Unicode: blocuri de 8, 16 și 32 de biți. În consecință, ele sunt numite utf-8, UTF-16 și UTF-32. Numele UTF reprezintă formatul de conversie Unicode. Fiecare dintre cele trei forme de codificare este un mijloc egal de reprezentare a caracterelor Unicode, are avantaje în diverse aplicații.
Aceste codificări pot fi folosite pentrureprezentarea tuturor caracterelor Unicode. Astfel, ele sunt pe deplin compatibile pentru soluții din diferite motive folosind diferite forme de codificare. Fiecare codificare poate fi convertită în mod unic în oricare dintre celelalte două fără pierderea datelor.

Principiul neimpozării
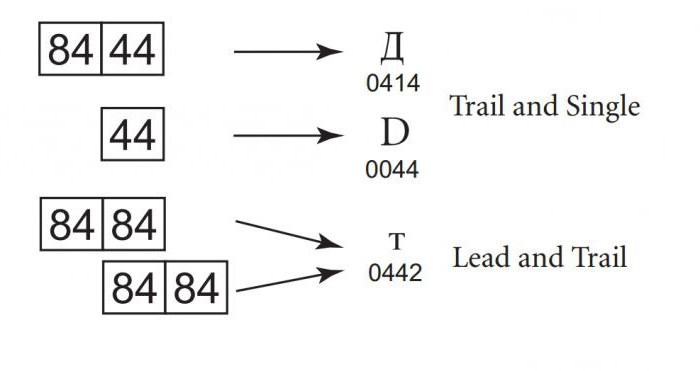
Fiecare dintre formele de codare Unicode este proiectată culuând în considerare inadmisibilitatea suprapunerii parțiale. De exemplu, Windows-932 generează caractere de la unul sau doi octeți de cod. Lungimea secvenței depinde de primul octet, astfel încât valorile octetului conducător în secvența a două octeți și un singur octet nu se intersectează. Cu toate acestea, valorile octetului unic și octetul de închidere al secvenței pot fi aceleași. Aceasta înseamnă, de exemplu, că atunci când căutați caracterul D (cod 44), îl puteți găsi în mod greșit introducând a doua parte a secvenței de doi octeți ai caracterelor "D" (cod 84 44). Pentru a determina ce secvență este corectă, programul trebuie să țină cont de octeții anteriori.
Situația devine mai complicată în cazul conducerii și al urmăririiocteții se vor potrivi. Aceasta înseamnă că pentru a inversa ambiguitatea, se va efectua o căutare inversă până la începutul textului sau o secvență clară de cod. Acest lucru nu este numai ineficient, dar nu este protejat împotriva posibilelor erori, deoarece un octet rău este suficient pentru a face întregul text necitit.
Formatul de conversie Unicode evitădin această problemă, deoarece valorile unității de stocare principale, de închidere și de stocare a informațiilor unice nu se potrivesc. Din acest motiv, toate codificările Unicode sunt potrivite pentru căutarea și compararea, fără a da vreun rezultat eronat datorită coincidenței diferitelor părți ale codului caracterului. Faptul că aceste formulare de codare respectă principiul non-alocării îi deosebește de alte codificări multi-asetice din Asia de Est.
Un alt aspect al non-intersecției codificărilor Unicodeeste că fiecare personaj are limite clar definite. Acest lucru elimină nevoia de a scana un număr nedeterminat de caractere anterioare. Această caracteristică a codificărilor este uneori numită auto-sincronizare. Distorsiunea unei unități de cod va duce la denaturarea unui singur caracter, iar caracterele înconjurătoare rămân intacte. În conversia format de 8-biți, în cazul în care indicatorul să octetul, începând cu 10xxxxxx (în cod binar) pentru a găsi este necesară începutul simbolului pentru una până la trei tranziții inverse.
consistență
Consorțiul Unicode sprijină pe deplin pe toate3 forme de codificare. Este important să nu se opună utf-8 și Unicode, deoarece toate formatele de conversie sunt implementări la fel de legitime ale formularelor de codare ale caracterelor Unicode.
Byte-orientare
Pentru a reprezenta simbolul UTF-32, aveți nevoie de o unitate de cod pe 32 de biți care să corespundă codului Unicode. UTF-16 - de la una la două unități de 16 biți. Și utf-8 utilizează până la 4 octeți.
Codificarea utf-8 a fost creată pentru a fi compatibilă cubyte orientate pe sisteme bazate pe ASCII. Cea mai mare parte a software-ului existent și practica tehnologiei informației pentru o lungă perioadă de timp bazat pe reprezentarea caracterelor într-o secvență de octeți. Multe protocoale depind de codificarea neschimbată ASCII și utilizează sau evită caracterele de control speciale. Un mod simplu de a se adapta la situații Unicode poate, folosind codificarea 8-biți pentru reprezentarea de caractere Unicode, orice caracter ASCII echivalent sau un caracter de control. Pentru aceasta, se intenționează codificarea utf-8.
Lungime variabilă
utf-8 este o codificare de lungime variabilă formată dinUnități de stocare de informații pe 8 biți ale căror biți de ordin înalt indică care parte din secvență aparține fiecărui octet. Un interval de valori este alocat pentru primul element al secvenței de cod, celălalt pentru elementele ulterioare. Aceasta asigură codificarea disjointă.

ASCII
codarea utf-8 suportă pe deplin codurile ASCII(0x00-0x7F). Aceasta înseamnă că caracterele Unicode U + 0000-U + 007F sunt convertite într-un singur octet 8 0x00-0x7F utf-și astfel devin imposibil de distins ASCII. Mai mult decât atât, pentru a evita ambiguitatea, valoarea 0x00-0x7F nu a folosit nici mai mult într-o reprezentare octet unic de caractere Unicode. Pentru a codifica simboluri neideograficheskih altele decât ASCII, folosind o secvență de doi octeți. Simboluri gama U + 0800-U + FFFF sunt reprezentate de trei octeți și coduri adiționale cu mai mult de U + FFFF necesită patru octeți.
Domeniul de aplicare
Codificarea utf-8 este de obicei preferată în protocolul HTML și similar cu acesta.
XML a devenit primul standard cu suport deplincodificări utf-8. Organizațiile implicate în standardizare, de asemenea, o recomandă. problemă de sprijin în adresa URL care este diferit de ASCII reprezintă caractere, a fost rezolvată atunci când W3C Consortium si grupul de inginerie IETF a ajuns la un acord cu privire la codificarea tuturor adreselor URL exclusiv în utf-8.
Compatibilitatea cu ASCII facilitează trecerea la o nouăsoftware-ul. Cu utf-8 majoritatea editorilor de text funcționează, inclusiv JEdit, Emacs, BBEdit, Eclipse și Notepad ale sistemului de operare Windows. Nici o altă formă de codare Unicode nu se poate lauda cu un astfel de suport din instrumente.
Avantajul codificării este acela că aceastaSe compune dintr-o secvență de octeți. String UTF-8 ușor să lucreze în C și în alte limbaje de programare. Aceasta este singura formă de codificare, ordinea nu are nevoie de etichete bytes BOM sau o declarație de codificare în XML.

auto-sincronizare
Într-un mediu care utilizează procesarea de caractere pe 8 biți, în comparație cu alte codificări multi-octeți, utf-8 are următoarele avantaje:
- Primul octet al secvenței de cod conține informații despre lungimea sa. Acest lucru crește eficiența căutării directe.
- Este mai ușor să găsim începutul caracterului, deoarece octetul inițial este limitat la o gamă fixă de valori.
- Nu există o intersecție a valorilor octeților.
Compararea avantajelor
codarea utf-8 este compactă. Dar când se aplică pentru codificarea caracterelor din Asia de Est (chineză, japoneză, coreeană, folosind caractere chinezești) se utilizează secvențe de 3 octeți. De asemenea, codarea utf-8 este inferioară altor forme de codare prin viteza de procesare. O sortare binară a șirurilor produce același rezultat ca un sortare binară Unicode.
Schema de codificare a caracterelor
Schema de codificare a caracterelor constă dintr-o formăcodificarea caracterelor și o metodă de aranjare a unităților de cod prin octet-cu-pixel. Pentru a determina schema de codificare cu standardul Unicode, este prevăzută utilizarea marcajului de ordonare inițială (BOM, marcaj de comandă byte).
Atunci când BOM este activat în utf-8, funcția de etichetăeste limitată numai de indicarea utilizării formularului de codificare. Nu există probleme de determinare a ordinii octeților în utf-8, deoarece dimensiunea unității de codare este un octet. Utilizarea BOM pentru acest formular de codificare nu este nici obligatorie, nici recomandată. BOM poate apărea în texte convertite din alte codificări care utilizează marca de ordine byte sau pentru semnătura codării utf-8. Este o secvență de 3 octeți de EF16 BB16 BF16.
Cum se configurează codarea utf-8
În HTML, codarea utf-8 este setată folosind următorul cod:
cap
˂meta http-equiv = "Content-Type" conținut = "text / html; charset = utf-8" ˂
În PHP, codificarea utf-8 este specificată folosind funcția header () la începutul fișierului după ce a fost setată valoarea nivelului de eroare:
˂? Php
error_reporting (-1);
header ("Content-Type: text / html; charset = utf-8");
Pentru a vă conecta la bazele de date MySQL, codificarea utf-8 este setată după cum urmează:
˂? Php
mysql_set_charset ("utf8");
În fișierele CSS, codificarea caracterului utf-8 este specificată după cum urmează:
@charset "utf-8";

Când salvați fișiere de toate tipurile, selectațicodarea utf-8 fără BOM, în caz contrar site-ul nu va funcționa. Pentru a face acest lucru, în programul DreamWeave, trebuie să selectați elementul de meniu "Modificări - Proprietăți pagină - Titlu / Codificare", modificați codificarea la utf-8. Apoi, trebuie să reîncărcați pagina, debifați caseta "Conectați semnăturile Unicode (BOM)" și aplicați modificările. Dacă un text din pagină sau din baza de date a fost introdus de un alt formular de codificare, atunci acesta trebuie reintrodus sau re-codat. Când lucrați cu expresii regulate, este obligatoriu să utilizați modificatorul u.
De asemenea, puteți salva fișierul în codificare utf-8 în Windows Notepad. După selectarea elementului de meniu "File - Save As ..." setați formularul de codificare necesar și salvați fișierul în codificarea utf-8.
În editorul de text Notepad ++, dacă codificarea diferă de utf-8, schimbați codarea și salvați-o în codificarea utf-8 prin intermediul elementului de meniu "Conversie la utf-8 fără BOM".

Nu există nicio alternativă
În contextul globalizării, atunci când este politic șilimitele limbajului sunt șterse, seturile de simboluri care au caracteristici locale devin mai puțin utile. Unicode este singurul set de caractere care acceptă toate localizările. Și utf-8 este un exemplu de implementare corectă a Unicode, care:
- sprijină o gamă largă de instrumente, inclusiv compatibilitatea cu codificarea ASCII;
- este rezistent la coruperea datelor;
- simplu și eficient în prelucrare;
- nu depinde de platformă.
Odată cu apariția dezbaterii utf-8 despre ce formă de codificare sau set de caractere este mai bună, au devenit lipsite de sens.
</ p>




